Dank eines umfangreichen Refactoring unseres Machine Learning-Moduls arbeitet die autonome Überwachung von Metriken jetzt deutlich effektiver. Deshalb können wir das zukunftweisende Feature nun allen Nutzern von Enginsight, unabhängig vom gebuchten Plan, zugänglich machen. Außerdem erhalten Partner mit dem Partner Operation Center eine Live-Übersicht ihrer Unterorganisationen.
für SaaS verfügbar: ab sofort | für On-Premises verfügbar: ab KW 30
Machine Learning für Alle!
Das Machine Learning-Modul ist in der Lage die Datenverläufe aller erfassten Server-Metriken zu analysieren, zu verstehen und den Normalbetrieb zu prognostizieren. Bei ungewöhnlichen Verläufen kategorisiert es die Abweichung als low, medium oder high und löst, wenn gewünscht, einen Alarm aus.
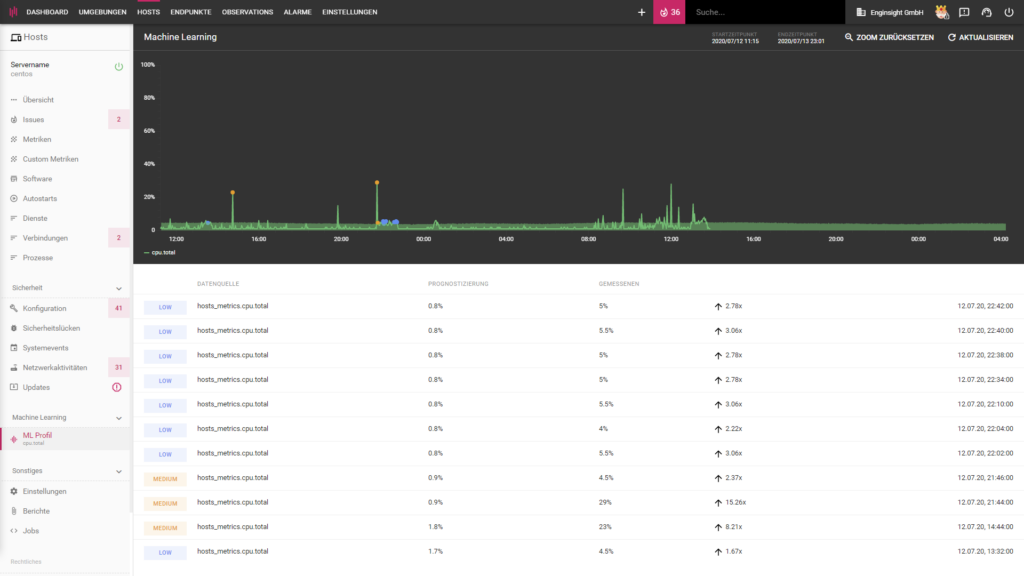
Mit wenigen Klicks zur autonomen ML-Überwachung
Die Überwachung kannst du entweder einzelnen Server-Metriken zuweisen oder du setzt auf die Verwendung von Tags. Wir empfehlen dir letzteres. Mittels Tags kannst du eine Vielzahl von Server-Metriken mit nur wenigen Klicks dauerhaft und autonom auf Anomalien untersuchen lassen.
Am besten erstellst du einen eigenen Tag für die Überwachung durch Machine Learning und ordnest ihn allen Servern zu, deren Metriken du überwachen möchtest. In der Konfiguration deiner ML-Metriken musst du in der Folge nur noch festlegen, welche Metriken der Server überwacht werden sollen.
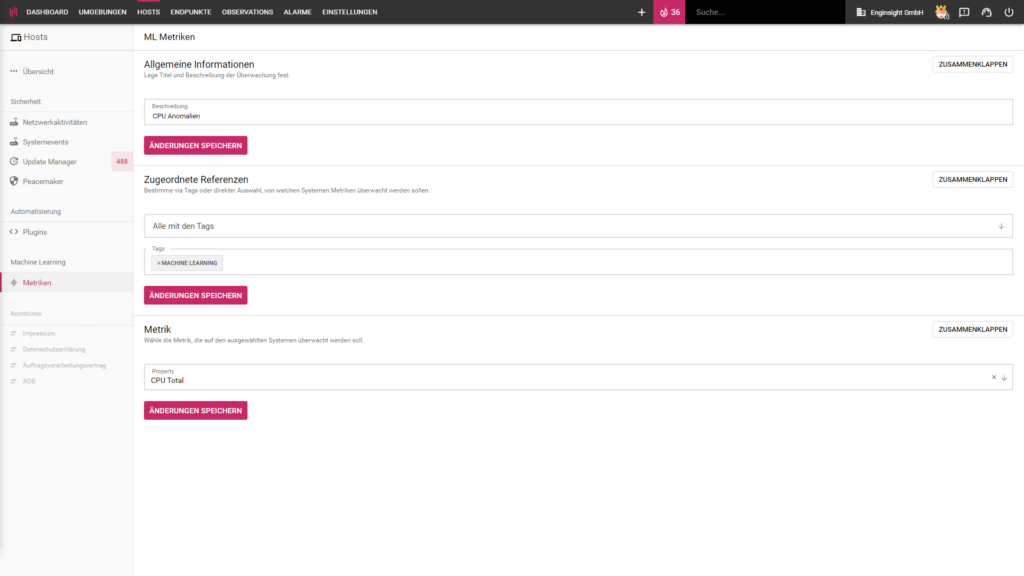
Neben der Überwachung der von Enginsight erfassten Standard-Metriken (CPU, RAM, Festplatten, Netzwerk usw.) kannst du auch deine eigenes definierten Custom Metriken mit dem Machine Learning-Modul überwachen. So kannst du Enginsight beispielsweise nutzen, um Anomalien im Verhalten von Datenbanken aufzuspüren.
Manueller Schwellwert oder Machine Learning?
Mit Enginsight ist beides möglich: Du kannst bei Alarmen auf Server-Metriken mit manuellen Grenzwerten arbeiten oder auf das Machine Learning setzen. Für welche der beiden Methoden du dich entscheidest, hängt von deinen individuellen Bedürfnissen und Vorlieben ab.
Das Vorgehen für beide Varianten ist ähnlich. Du erstellst einen neuen Alarm und wählst als Referenz entweder einen einzelnen Server oder einen Tag, um den Alarm auf mehrere Server zu schalten. Willst du mit dem Machine Learning arbeiten, musst du lediglich die Bedingung „Machine Learning: Ungewöhnliches Verhalten“ auswählen. Für einen Alarm mit manuellem Schwellwert wählst du die entsprechende Bedingung (bspw. CPU Total) und legst deinen Grenzwert fest (z.B. größer als 90% in einem Intervall von 5 Minuten).
Im Vergleich zu dem harten Schwellwert, bekommt die durch Machine Learning gestützte Alarmierung feinere Stufen mit. Gerade wenn eine Vielzahl an Servern mit unterschiedlichem Normalverhalten überwacht werden sollen, erspart sich der Regelersteller viel Arbeit, da das Feintuning der Alarme entfällt. Außerdem lässt sich so die Anzahl an falsch-positiven Alarmen reduzieren. Natürlich lassen sich auch beide Wege kombinieren, um für jede Server-Metrik die spezifisch passende Alarmart zu nutzen.
Partner Operation Center
Dank seiner Mandantenfähigkeit ist Enginsight das ideale Tool für IT-Dienstleister, um die IT-Umgebung ihrer Kunden zu managen, überwachen und abzusichern. Dazu legt ein Partner für jeden Kunden eine Unterorganisation an, in der er die IT des Kunden einpflegt.
In Version 2.9.0 haben wir mit dem Asset Operation Center das erste unserer neuen Operation Center eingeführt. In ihnen bündeln wir künftig in übersichtlicher Form die große Menge der von Enginsight aggregierten Daten in Meta-Live-Ansichten.
Mit dem Partner Operation Center gehen wir den zweiten Schritt und geben speziell unseren Partnern eine neue Schaltzentrale für ihre täglich Arbeit. Auf einen Blick erhalten sie eine Live-Übersicht über den Zustand der IT aller Unterorganisationen.
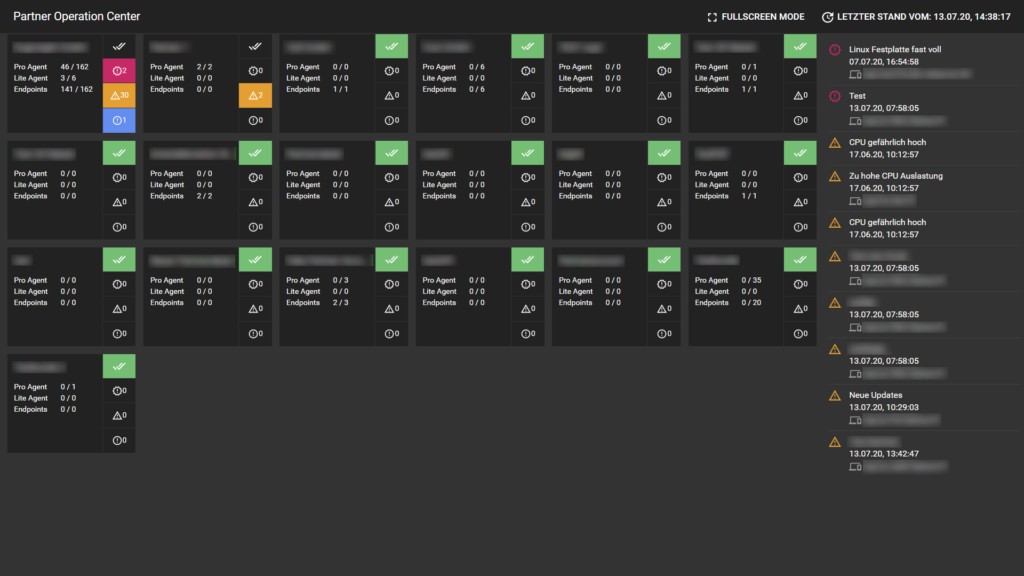
Löst Enginsight in einer der Unterorganisationen einen Alarm, taucht er unmittelbar im Partner Operation Center auf. Es lassen sich Details zum Alarm ausgeben und in die entsprechende Organisation wechseln. Im Fullscreen Modus dauerhaft auf einen Bildschirm gelegt, macht das Partner Operation Center auch in einem Security Operation Center eine gute Figur.